
Python kullanarak bir SQL Server’daki (bu örnekte Azure SQL veritabanı) bir tabloda yer alan veriyi, Parquet formatında AWS S3 bucket’ına aktarmak için gerekli kodu kısaca inceleyelim.
Ön gereksinimler
- Azure SQL veritabanın dışarıdan erişime açık olması gerekiyor.
- AWS S3 için, Read ve Put yetkilerine sahip bir kullanıcı ve bu kullanıcı için oluşturulmuş Access Key ID ile Secret Access Key.
- Kodun çalıştırılacağı ortamda şu Python paketlerinin kurulu olması gerekiyor: io, datetime, pyodbc, pandas, boto3
Azure SQL veritabanından veriyi çekme
Örnek olarak aşağıdaki desende, tablo_1 adında ve içinde deneme için iki satırlık veri olan bir tablomuz olduğunu düşünelim.

import pyodbc
import pandas as pd
from datetime import datetime
today = datetime.today()
# Read from SQL Server
server = '{sunucu-adı}.database.windows.net'
database = '{veritabanı-adı}'
username = '{kullanıcı-adı}'
password = '{şifre}'
driver= '{SQL Server}'
conn = pyodbc.connect('DRIVER='+driver+';SERVER=tcp:'+server+';PORT=1433;DATABASE='+database+';UID='+username+';PWD='+ password)
cursor = conn.cursor()
query = "SELECT id, first_name, last_name, email, insert_date from dbo.tablo_1"
df = pd.read_sql(query, conn)
display(df)Kodu çalıştırdığımızda aşağıdaki gibi bir çıktı elde etmemiz gerekir:

Burada display(df) ifadesini çıktıyı görmek için ekledik.
Dataframe’i S3’e yazma
Buradaki örnekte ttbucket002 adında bir bucket’ımız var. Bunun içinde bulunan test klasörüne deneme_20230207.parquet dosyasının yazılmasını bekliyoruz. Buradaki Access Key ID ve Secret Access Key değerlerini S3 bucket ile ilişkilendirilmiş user’a ait security credential‘lar gelmeli.
from io import BytesIO
import boto3
from datetime import datetime
today = datetime.today()
p_buffer = BytesIO()
df.to_parquet(p_buffer)
s3_resource = boto3.resource(
service_name='s3',
region_name='eu-west-1',
aws_access_key_id='XXXXXXXXXXXXXXXXXXXX',
aws_secret_access_key='XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
)
bucket_name = "ttbucket002"
input_folder = "test"
current_date_format = today.strftime("%Y%m%d")
data_set_name = "deneme"
file_format = ".parquet"
file_path = input_folder + "/" + data_set_name + "_" + current_date_format + file_format
s3_resource.Object(bucket_name, file_path).put(Body=p_buffer.getvalue())file_path değişkenini, daha dinamik bir yapıda olması için parametrik olarak düzenledik ama bu klasör yolunu doğrudan da verebilirdik. Kodu çalıştırdığımızda parquet dosyasını belirttiğimiz klasöre yazmış olmalıdır. Bunu iki şekilde kontrol edebiliriz: AWS S3 konsol arayüzünden ve Python kodu ile sorgulayarak.
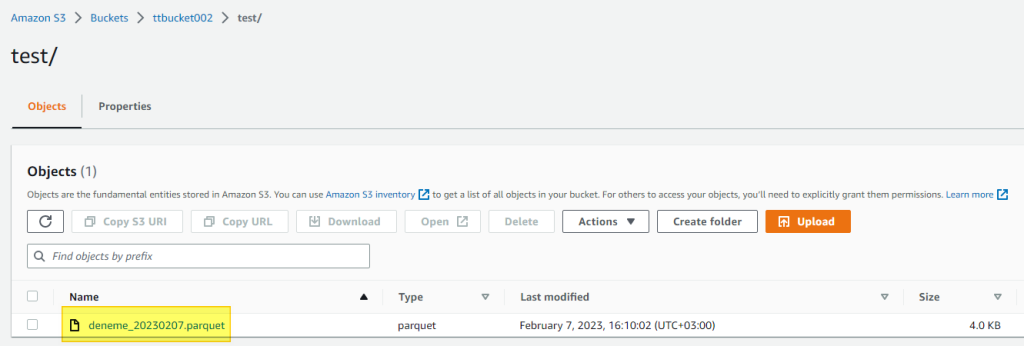
AWS S3 konsolundan kontrol
AWS S3 yfasından test klasörü içinde girdiğimizde dosyanın oluşmuş olduğunu görüyoruz.
Python kodu ile sorgu
Aşağıdaki Python kodu ile verdiğimiz klasör içindeki dosyaları listeleyebiliriz:
for obj in s3_resource.Bucket('ttbucket002').objects.all():
print(obj)Çıktıyı kontrol ettiğimizde dosyayı görüntüleyebiliyoruz.

Bu kodu farklı ortamlarda da kullanabilirsiniz. Örneğin Azure üzerinde Automation Runbook‘lar kullanarak ya da NiFi ile aktarılabilir.